



こんにちは、情報系大学生のハル(Blog_IT_haru)です。
今回は、4年生になり、研究室に配属され、そこでサイトのデータを使用するために、Web Pageを保存しておきたいと思ったので、ウェブスクレイピングを以下にまとめておきます。
自然言語処理の準備として行ったので、研究室の先輩・教授からおすすめされて私も読んだ本も紹介しておきます。興味ある方はぜひそれも見ていただけると嬉しいです。

ウェブスクレイピングとは?法的問題は?
ウェブスクレイピングとは、以下のようなことを言います。
Webスクレイピングとは、WebサイトからWebページのHTMLデータを収集して、特定のデータを抽出、整形し直すことである。 Webスクレイピングを行うことで、Webページを対象として、あたかもWeb APIを利用しているかのようにデータを効率的に取得・収集することが可能になる。用途の例としては、部分的にコンテンツを取り出して携帯電話向けのコンテンツを生成したり、小見出しの一覧を生成したり、といった使い方あある。Webスクレイピングは様々な手段で実現可能であるが、PHPやPerlといったスクリプト言語を使用して行われることが多い。(「ウェブスクレイピング」の意味や使い方 わかりやすく解説 Weblio辞書引用)
また、ウェブスクレイピングは法的には引っかからなくても、規約違反になる可能性もあるので、注意が必要です。
スクレイピングは違法?3つの法律問題と対応策を弁護士が5分で解説から、法的な問題について参考にさせていただきました。
①著作権法上の問題・②利用規約との抵触・③サーバーへの過度なアクセスによる3つの問題の可能性があります。
①著作物をコピーしたり、自社のサーバに保存するなどの行為をすると、原則として違法となってしまいます、そのため、スクレイピングをする際は、あくまで「情報解析」を目的としたものでなければいけないようです。
②Twitterなどのサービス利用規約にも書いてあるように、スクレイピングを禁止しているような場合は、利用規約違反となり、民法上の債務不履行や不法行為に該当する可能性があるようです。
③サーバーへの負荷により、アクセス障害などが起こると、偽計業務妨害容疑で逮捕されるケースも過去にあったようです。そのため、自然検索程度の量にするのがベターです。
具体的な保存方法
今回の私の場合、必要なサイトのリンクがリストのように一覧で見ることができるページがあったので、以下のような手順で行いました。
- Google Chromeでデベロッパーツールで、HTMLを保存(Chrome)
- そのHTMLからaタグの内容を取り出してcsvファイルに保存(Python)
- csvをリスト化して、それをfor文で保存(Python)
環境
Windows10
Jupyter Notebook
実際のコード
- Google Chromeでデベロッパーツールで、HTMLを保存(Chrome)
Google Chromeで必要なサイトを開き、デベロッパーツールでCopy elementをして、メモ帳などで、HTMLファイルで保存すればOKです。
このとき、リストの部分など、必要な部分のみをコピペして保存します。 - そのHTMLからaタグの内容を取り出してcsvファイルに保存(Python)
from bs4 import BeautifulSoup import csv # ファイルを開く with open('ファイル名.html', 'r', encoding='utf-8') as f: # BeautifulSoupで解析 soup = BeautifulSoup(f, 'html.parser') # aタグを全て取得 a_tags = soup.find_all('a') # aタグからtitleとhref属性を取得して、CSVファイルに書き込む with open('ファイル名.csv', 'w', newline='', encoding='utf-8') as csvfile: writer = csv.writer(csvfile) for a_tag in a_tags: title = a_tag.get('title') href = a_tag.get('href') writer.writerow([title, href]) # ファイルが生成されたことを表示する print('ファイル名.csvファイルが生成されました')
- csvをリスト化して、それをfor文で保存
import pandas as pd import os import requests #csvのデータをリストに格納 sites = pd.read_csv("ファイル名.csv", header=None).values.tolist() folder = "./フォルダ名/" # 保存先のパス if not os.path.exists(folder): # フォルダが存在しなければ作成 os.makedirs(folder) for i, site in enumerate(sites): title = site[0] url = site[1] site_data = requests.get(url) with open(os.path.join(folder, f"{i+1}_{title}.html"), "w", encoding='utf-8') as f: f.write(site_data.text) print(f"{title} の書き込みが完了しました") print("終了")
コードの解説
一応、コードの一つひとつの解説を載せておきます。
■BeautifulSoupについて
https://ai-inter1.com/beautifulsoup_1/
『BeautifulSoup(解析対象のHTML/XML, 利用するパーサー)
1つ目の引数には、解析対象のHTML/XMLを渡します。
2つ目の引数として解析に利用するパーサー(解析器)を指定します。』
『find_all()は引数に、検索するHTMLタグを渡し、引数に一致する 全ての 要素を取得します。』
■csvについて
https://note.nkmk.me/python-csv-reader-writer/
csv.writerは、CSVファイルの書き込みを行うために使います。
『コンストラクタcsv.writer()の第一引数にopen()で開いたファイルオブジェクトを指定』します。
今回でいうと、csvfileを使っています。
■with open('ファイル名.html', 'r', encoding='utf-8') as f: について
以下のサイトが参考になります。
https://note.nkmk.me/python-file-io-open-with/#open-with
『with open() as xxx:のxxxには任意の名前を使用できる。open()でオープンしたファイルオブジェクトにxxxという名前をつけてブロック内で使用するイメージ』です。
rは、読み込み用でファイルをオープンするという意味です。
encoding='utf-8'は、文字コードを指定しています。
『encodingのデフォルト値はプラットフォーム依存。locale.getpreferredencoding()で確認できる。』ようです。
以下のコードが参考になります(引用)
import locale
print(locale.getpreferredencoding())
# UTF-8
■with open('ファイル名.csv', 'w', newline='', encoding='utf-8') as csvfile:
wは書き込みモードでファイルをオープンするというイメージです。
newlineは、一行空きを防ぐためのものです。
https://tonari-it.com/python-csv-writer-writerow/より。
■a_tagのところで使っているgetについて
今回は、aタグのなかに、tiltle="タイトル"、href="URL"という感じにデータを取得していたので、それを利用しました。
以下の部分ですね。
title = a_tag.get('title')
href = a_tag.get('href')
辞書からキーで取得するメソッドです。
https://note.nkmk.me/python-dict-get-key-from-value/
以下のコードが参考になります。
d = {'key1': 'aaa', 'key2': 'aaa', 'key3': 'bbb'}
value = d['key1']
print(value)
# aaa
■writer.writerow
https://tonari-it.com/python-csv-writer-writerow/が参考になります。
要は、csvに書き込むときのものです。
import csv
with open('test.csv','a') as f:
writer = csv.writer(f)
writer.writerow([1,'スパム','500円'])
writer.writerow([2,'卵','168円'])
writer.writerow([3,'ベーコン','1,250円'])
にすると、
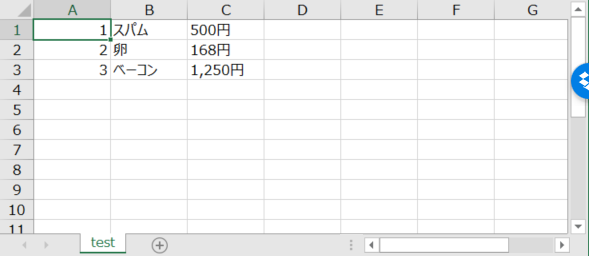
のようにできます。
■csvのデータをリストに格納
sites = pd.read_csv("ファイル名.csv", header=None).values.tolist()
は、https://kaworu.jpn.org/kaworu/2018-06-02-1.php をそのまま参考にしました。
■フォルダが存在しなければ作成
os.path.existsは、フォルダがあるかどうかを判断しています。
また、 os.makedirs(folder)は、フォルダがなければ作成するものになります。
if not os.path.exists(folder): # フォルダが存在しなければ作成
os.makedirs(folder)
https://khid.net/2019/12/python-check-exists-dir-make-dir/を参考にしました。
■enumerate
インデックスも取得するためのものです。
for i, name in enumerate(l):
print(i, name)
# 0 Alice
# 1 Bob
# 2 Charlie
https://note.nkmk.me/python-enumerate-start/が参考になります。
■site_data = requests.get(url)
requests.getで、Web Pageを取得することが出来ます。
より詳しく知りたい方は以下のウェブサイトを見ると良いかもです。
https://note.nkmk.me/python-requests-usage/
■os.path.join
パスを結合するときに使うものです。
import os
# log と sample.logを結合し、log/sample.log というパスを作るサンプルプログラム
join_path = os.path.join("log", "sample.log")
print(join_path)
https://aiacademy.jp/media/?p=1527より。
■f.write(site_data.text)
f.write('こんにちは\n')
という感じで、テキストファイルに書き込むことができます。
fは開いたtxtファイルを示しています。
https://www.javadrive.jp/python/file/index3.htmlより
■{title}
今回は、titleのところに書いてあるものを取得したかったので、このように取得しています。
参考にしたサイト
自然言語処理のおすすめ本
今回は、私は研究で、自然言語処理をしようと思い、スクレイピングを行いました。
そこで、おすすめの本を以下紹介しておきます。
(先輩・教授からおすすめされて、私も読んだものです。)
放送大学の自然言語処理の教科書は、自然言語処理について体系的に学びたい方におすすめです。
内容は結構難しい印象なので、調べながらやるのをおすすめします。(私は研究室のゼミで使っています。)
キテレツおもしろ自然言語処理は、結構面白おかしく書いてくれていて、演習とか、実際に手を動かしてみるのにおすすめです。が、結構演習メインと言うか、使ってみて、みたいな感じなので、放送大学の教材で学びつつ、やるのが良いかなと思います。
最後のPython自然言語処理入門は私的に一番オススメです。
教科書的な要素もありつつ、演習を色々できるので、キテレツおもしろ自然言語処理よりは、汎用的な内容になっています。
興味ある方はぜひ。



まとめ
いかがでしたか?
意外と簡単に、スクレイピングが出来ることが分かったと思います。
また、今回の方法だと、最初にデベロッパーツールから必要なhtmlの部分のみコピーして、そのファイルをローカルに保存して、1ページずつスクレイピングしているので、元のサイトにかかる負荷は低いかなと思います(普通のブラウジングに近い)
私のように、ウェブ上のデータを使って、研究したいと考えている方に役立つと嬉しいです。
また、今後は自然言語処理についてもメモがてら共有できたらと思っています。
ぜひ参考にしてみてください。
この記事がいいな、と思ってくれたら、SNSなどで拡散したり、
ブックマークやコメントなどしてくれると励みになります!
下の方とサイドバーにある、サポートもお待ちしています!
更に、読者になってくれたら、お返しに私も読者になります!
また、この記事の内容についてなにかありましたら、
お問い合わせ、コメント、TwitterのDMなどによろしくお願いします。
それでは。
![]()